Part 1: Forward and Reverse Geocoding using FourSquare's TwoFishes


Last year, I created the Amazon Alexa Skill for Cork Hounds which takes a City/State, and responds with the nearest fully dog friendly vineyard. When I first started that project, I re-read Google's Geocoding API terms of service, and confirmed that without a Business/Enterprise account we could only use their service if the resulting data would be plotted to a Google Map. Because I was coding a voice-only skill, I needed to find an alternative geocoding service/tool. I wanted something free, that could be containerized in some way; bonus if it could also handle reverse geocoding. That's when I discovered Foursquare's TwoFishes.
There is some good web content on TwoFishes. You can read about TwoFishes; there is a Forbes blog, written back when TwoFishes was first released. Also, the creator of TwoFishes, David Blackman was interviewed by Fast Company for a web article. TwoFishes was also presented at the Free Open Source Software 4 Geospatial North America. Foursquare is leading the charge with some interesting work on a global polygon gazetteer, Quattroshapes which they use with TwoFishes for bounding place searches. There is a blog on the Foursquare/Medium engineering blog space.
Advantages: TwoFishes is an active project written and maintained by the brilliant geospatial professionals at Foursquare. It is still being used to power the Foursquare featureset. It offers world-class course, splitting, forward geocoding and polygon based reverse geocoding. And there are good examples of using it in a Docker container.
Disadvantages: It is written in two languages I haven't used extensively (Scala and Python). Also, it relies on a build framework that I had never even heard of (Pants). For those of you that are familiar with these languagues/frameworks, you'll have a leg up. I noticed that the Foursquare geo team does not respond to issues on github frequently, and they stopped supporting their twofishes.net site, which is where they previously hosted binaries and pre-built geodatabases. Combined, I would likely have to go deeper on this than I wanted to get it working. (And I was right).
Overview
I have been using TwoFishes for over a year now, and am currently hosting a container on AWS ECS. It handles forward geocoding of city/state addresses for our Alexa Skill, and reverse geocoding of decimal degrees from the web and mobile application to identify the State in which a search is conducted for message handling.
In Part 1 of this blog I'll focus on building the Mongodb geospatial database/indices for forward and reverse geocoding. In Part 2 of this blog, I'll cover building and managing a TwoFishes Container with a volume for speedier start-ups, and how to test that its working.
Building the Database/Indices
I'll subdivide this into two stages:
- Reverse Geocoding; Building a Shapefile with Geoname Concordances
- Forward Geocoding & Building the Actual Database/Indices
If you want to do reverse geocoding, you need to build a shapefile with references to the Geonames dataset. From there, you can move into build the forward geocoding and reverse geocoding database.
If you don't want to do reverse geocoding, you can skip the next section, and go straight to 'Forward Geocoding & Building the Actual Database/Indices'.
Reverse Geocoding; Building a Shapefile with Geoname Concordances
Ultimately, TwoFishes uses polygon bounding boxes to map a set of coordinates, comprised of a latitude and longitude in decimal degrees to a place. The place data can be very specific (e.g. a town, municipality, etc) or very general (e.g. a country, state, or county). What you get back from TwoFishes depends on what type of polygon data you provide when building the reverse geocoding index(es).
I am only interested in getting State-level (Admin 1) data within the US back from TwoFishes. Therefore, I wasn't interested in global datasets. However, if you are, I suggest you look at the Quattroshapes dataset built by Foursquare for global polygon data. Note: These files do not have references to the Geonames dataset, so you'll need to use David Blackman's shapefile utilities - shputils - to generate a new shapefile that contains geonames references baked in. I touch on using the Shape Geoname Matcher (shape-gn-matchr.py) at the end of this section; if you're using quattroshapes, you can skip to "Geoname Concordances".
Building the Geonames Database
To build the initial set of Admin 1 polygons for the United States, I used my Windows machine. All the following work was performed from a DOS CMD prompt as Administrator. You will want to refer to the instructions provided on the TwoFishes Readme entitled "Reverse Geocoding and Polygons". If you follow those instructions, you'll likely run into the same problems I did. So I'll augment their instructions with some caveats and fixes.
Setup
First, you'll want to install or get access to a Postgres database with Postgis installed. You can download Postgres here, and Postgis here. I installed one locally. This database is only used to create the shapefiles; after we're done you can remove it. I used a 9.2 version of Postgres for this exercise.
Next, you'll follow the instructions for building a Geonames Postgres/Postgis database, referenced on the FSQIO/TwoFishes Readme. Here are some minor alterations to those instructions to overcome some issues that I ran into; if I skip over any of their instructions, assume they work as described.
Create the Database
If you are unfamiliar with Postgres, know that these commands reference CLI tools in the postgres bin directory. For example: C:\postgreSQL\9.2\bin. You can follow suit, or just do all of this in PSQL. You can find a manual on PSQL here.
Insert the Data
You're going to run these copy commands from psql or an SQL window in pg-admin.
If you're using Windows, you may run into a permissions problem when using the COPY command. For starters, the answer provided by Kevin in this Stackoverflow thread worked for me; providing 'Everyone' permission to the geonames data. Also, you'll want to use fully qualified paths in the copy statement (e.g. 'allcountries.txt' => 'C:\Users\<user>\...\allCountries.txt').
When running the first copy statement, you may see an error regarding the size of the 'cc2' field. In the latest geonames data (which is updated all the time), the cc2 field needs to be bigger. You can fix this upfront during the creation of the table, or alter it. I increased 'cc2' to varchar(200). To alter it, simply run:
ALTER TABLE geoname ALTER COLUMN cc2 TYPE varchar(200);
If you are on a Windows box, you may get an error message regarding UTF-8 encoding. Essentially, Postgres defaults to Windows-1252 encoding, and the Geonames data is in UTF-8. The accepted answer on this Stackoverflow thread worked for me. You'll want to run the following command:
SET CLIENT_ENCODING TO 'utf8';
Lastly, ingesting the countryInfo.txt file didn't work without some changes. For starters, I had to delete all the comments at the top of the file, leaving only the header row.
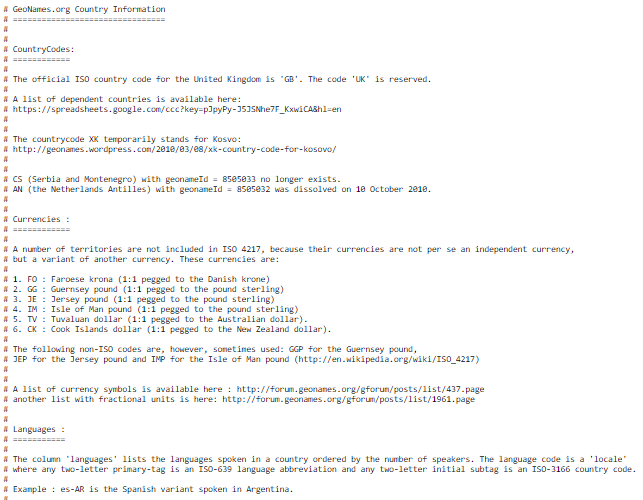
Credit: http://download.geonames.org/export/dump/countryInfo.txt
Second, I had to convert the file to comma delimited, rather than use its native tab delimited format. I did this quickly by uploading to a Google spreadsheet, and then downloading as CSV.
Now, you can use the following command to ingest it, changing the fully qualified path for 'countryInfo.csv' to match your file location:
copy countryinfo (iso_alpha2,iso_alpha3,iso_numeric,fips_code,name,capital,areainsqkm,population,continent,tld,currencycode,currencyname,phone,postalcode,postalcoderegex,languages,geonameid,neighbors,equivfipscode) from 'C:\Users\<USER>\geonames\countryInfo.csv' with (FORMAT csv, NULL '', HEADER true);
Continue with the instructions for setting up a Geonames postgres database. Once complete, you can move onto the next section: Geoname Concordances.
Geoname Concordances
In order to convert decimal degrees to metadata like country, state, region, etc., TwoFishes needs bounding polygons that map to Geonames data. Therefore, we need polygons that have built-in references to Geonames IDs, which TwoFishes will parse to build its revgeo index(es).
Starting with Bounding Polygons
If you are starting with Quattroshapes, then you already have starting polygons. However, if you aren't using Quattroshapes, you will need to download some. For US data in general, we can use TIGER/Line data provided by the Census Bureau. There is a lot of detailed shape, line an metadata available through their site. I am not a geospatial expert, and haven't worked with much of this data. You can read up on the structure of the data provided here. Specifically, you can find place/locality data, state data and county data. There are other options as well, but these should be your goto datasets.
As it says in the 'Format/Structure PDF' linked above, the format of these files is as follows:
tl_2010_extent_layer.extension
Where:
tl = TIGER/Line
2010 = the version of the files
extent = parent geography entity ID code (variable length of two to five characters). The entity ID code identifies the geographic extent by specific entity for which the file contains data. It is of variable length depending on the type of file:
- American Indian area-based: 4-digit numeric American Indian area Census code
- Nation-based: 2-character abbreviation – “us”
- State-based: 2-digit numeric state FIPS code
- County-based: 5-digit numeric county FIPS code
Credit: US Census Bureau.
You can find the FIPS codes for states on Wikipedia. Therefore, if you want to do place data for New Mexico, you can download the following file: ftp://ftp2.census.gov/geo/tiger/TIGER2010/PLACE/2010/tl_2010_35_place10.shp
If you want all US counties, you can download the following file:
ftp://ftp2.census.gov/geo/tiger/TIGER2010/COUNTY/2010/tl_2010_us_county10.shp
Working with shputils
Next, we'll use the shputils/shape-gn-matchr.py script from David Blackman's Shapefile utilities. Make sure you have pip installed for python; this command will install pip if its missing.
python -m ensurepip --default-pip
Next, you'll want to clone/download the https://github.com/blackmad/shputils repository. And take a look at the shape-gn-matchr.py to get a feel for how it works, and the options it takes. The Foursquare team provides some examples for processing locality and country boundaries using the polygon shapes we just downloaded.
For example, Foursquare gave us some examples, one of which I've pasted below. This assumes you gave your geonames postgres database a password, that you called your geonames database 'geonames', and you are processing all US counties at the time of the 2010 census using the tl_2010_us_county10.shp (using a relative path location) files you downloaded earlier.
python ../shputils-master/shape-gn-matchr.py --dbname=geonames --dbpass=YOUR_PASSWORD --shp_name_keys=NAME10 --allowed_gn_classes='' --allowed_gn_codes=ADM2 --fallback_allowed_gn_classes='' --fallback_allowed_gn_codes='' tl_2010_us_county10.shp gn-us-adm2.shp
This will produce a collection of files associated with gn-us-adm2.shp. For the above command to succeed.
Installing Dependencies
You will likely need a bunch of libraries unless you work with shapefiles in python regularly; check out the python dependencies for shape-gn-matchr.py on github. Couple thoughts regarding windows installs:
Install osgeo4w to get the geos_c.dll library in order to install Shapely. Add The bin directory to your PATH (osgeo4w/bin) and relaunch your CMD window. There is an issue logged on github that gives context. Then install shapely via python -m pip install shapely.
You can get a lot of the other needed libraries from University of California, Irvine, provided by Christoph Gohlke at their pythonlibs site in WHL binary Windos installer format.
To install these binaries, you will need pip version 9 or newer, along with some other dependencies. From their site: "Many binaries depend on numpy-1.14+mkl and the Microsoft Visual C++ 2008 (x64, x86, and SP1 for CPython 2.7), Visual C++ 2010 (x64, x86, for CPython 3.4), or the Visual C++ 2017 (x64 or x86 for CPython 3.5, 3.6, and 3.7) redistributable packages."
I found these libraries using Google. I have a 64 bit system, and am using Python 2.7. Therefore I retrieved the Microsoft Visual C++ 2008 x64, Visual C++ 2010 x64, Visual C++ 2017, and the Microsoft Visual C++ 9.0 compiler for Python 2.7 libraries from Microsoft. And I downloaded numpy‑1.14.5+mkl‑cp27‑cp27m‑win_amd64.whl from the pythonlibs site. Notice the '27' and 'amd64' in the filenames for the WHL files; that tells you that the download is for Python 2.7 and a 64bit machine.
To install the WHL files once downloaded, use python -m pip install <FILE_NAME>.whl
Next, I had to install GDAL to get the 'cpl_conv.h' library for Fiona to install. You can read an issue logged on github for context. Then I could install Fiona. I grabbed the Fiona‑1.7.12‑cp27‑cp27m‑win_amd64.whl file.
I also had to install Psycopg, which is a PostgreSQL database adapter. I grabbed the psycopg2‑2.7.5‑cp27‑cp27m‑win_amd64.whl file.
You may need other libraries, but you get the point on how to get the files you need and install them.
Finishing up
After all this, I was able to get shape-gn-matchr.py to run, and output the needed shapefile with Geonames concordances. And, you won't need the Postgres Geonames database you built for the remainder of the instructions.
I suggest you validate the shapefile (.shp) by looking at it in a GIS tool (e.g. QGIS https://www.qgis.org).
Forward Geocoding & Building the Actual Database/Indices
If you haven't already, clone/download the FSQIO repository.
If you built the shapefile for reverse geocoding, put the shapefile (the shp, shx, cpg, dbf) into the fsqio/src/jvm/io/fsq/twofishes/indexer/data/private/polygons folder. You will need to create the private/prolygons folder, it isn't in the clone repo tree structure.
Now, we can follow the standard instructions for building the Forward geocoding database, starting with 'First Time Setup' on their Readme. For the following, I switched over to an AWS Amazon Linux m5.xlarge machine. Building the database and indices for Forward and Reverse geocoding takes some horsepower.
Download the Geonames Data
First, we need to download the Geonames data again. This portion of the setup doesn't use the Geonames postgres database we built earlier. If you want to download country: ./src/jvm/io/fsq/twofishes/scripts/download-country.sh [ISO 3166 country code] (For example US, GB, etc). If you want to download world: ./src/jvm/io/fsq/twofishes/scripts/download-world.sh
I ran ./src/jvm/io/fsq/twofishes/scripts/download-country.sh US to get the US data.
Install Dependencies
Next, I needed to install and start the Mongo DB on the Amazon Linux machine I was running, and I found good instructions online. Also, you'll want to install install gcc with yum install gcc. And finally, install the OpenJDK with sudo yum install java-1.8.0-openjdk-devel.
Initialize the Database
Then, from the command line, you can run mongod --dbpath /local/directory/for/output/, where the directory is the location you want to put your database. I created a folder called us-data.
Now, we build the Mongo database/indices used by TwoFishes with the geonames data we just downloaded, and optionally, our shapefile for reverse geocoding. Note, you won't need Mongo on the server where you run TwoFishes; it is only used to build the database/indices.
Build the Database/Indices
To import import one or more countries using ./src/jvm/io/fsq/twofishes/scripts/parse.py -c US /output/dir, where output/dir is the us-data folder I created earlier. Also, you can specify list of countries separating them by comma: US,GB,RU. If you want to import the world: ./src/jvm/io/fsq/twofishes/scripts/parse.py -w /output/dir. If you are using the shapefile for reverse geocoding, you use the --output_revgeo_index argument on the parse command. Therefore, in my case I ran sudo ./src/jvm/io/fsq/twofishes/scripts/parse.py -c US --output_revgeo_index us-data
If the job completes successfully, you may see some metrics output in json format like those below. If you don't see these metrics at the end of the parse.py job, it may not have completed successfully.
856507 INFO i.f.t.i.i.geonames.GeonamesParser$ - {
"counters" : {
"PolygonLoader.indexPolygon" : 3136,
"PolygonLoader.removeBadPolygon" : 5,
"jvm_gc_PS_MarkSweep_cycles" : 11,
"jvm_gc_PS_MarkSweep_msec" : 52599,
"jvm_gc_PS_Scavenge_cycles" : 258,
"jvm_gc_PS_Scavenge_msec" : 33127,
"jvm_gc_cycles" : 269,
"jvm_gc_msec" : 85726,
"s2.akkaWorkers.CalculateCover" : 3136
},
... shorted for brevity ...
"metrics" : {
"coverClippingForRevGeoIndex_msec" : {
"average" : 223,
"count" : 3136,
"maximum" : 10498,
"minimum" : 1,
"p50" : 142,
"p90" : 427,
"p95" : 637,
"p99" : 1283,
"p999" : 5758,
"p9999" : 10498,
"sum" : 700281
},
... shortened for brevity ...
"io.fsq.twofishes.indexer.output.PolygonIndexer_msec" : {
"average" : 2521,
"count" : 1,
"maximum" : 2586,
"minimum" : 2586,
"p50" : 2586,
"p90" : 2586,
"p95" : 2586,
"p99" : 2586,
"p999" : 2586,
"p9999" : 2586,
"sum" : 2521
},
"io.fsq.twofishes.indexer.output.PrefixIndexer_msec" : {
"average" : 250815,
"count" : 1,
"maximum" : 258239,
"minimum" : 258239,
"p50" : 258239,
"p90" : 258239,
"p95" : 258239,
"p99" : 258239,
"p999" : 258239,
"p9999" : 258239,
"sum" : 250815
},
"io.fsq.twofishes.indexer.output.RevGeoIndexer_msec" : {
"average" : 13008,
"count" : 1,
"maximum" : 12825,
"minimum" : 12825,
"p50" : 12825,
"p90" : 12825,
"p95" : 12825,
"p99" : 12825,
"p999" : 12825,
"p9999" : 12825,
"sum" : 13008
},
... shortened for brevity ...
"s2CoveringForRevGeoIndex_msec" : {
"average" : 106,
"count" : 3136,
"maximum" : 10498,
"minimum" : 2,
"p50" : 63,
"p90" : 212,
"p95" : 286,
"p99" : 521,
"p999" : 1418,
"p9999" : 10498,
"sum" : 332616
},
"totalCovering_msec" : {
"average" : 330,
"count" : 3136,
"maximum" : 11603,
"minimum" : 4,
"p50" : 212,
"p90" : 637,
"p95" : 950,
"p99" : 1915,
"p999" : 10498,
"p9999" : 11603,
"sum" : 1035225
}
}
}
Troubleshooting parse.py
The first time I ran the parse.py, I eventually received a "Java heap space, GC Overhead limit exceeded" error. To fix this, I edited the parse.py to increase its max memory to 10Gig. If you run into that problem, find the following line:
jvm_args = ['-Dlogback.configurationFile=src/jvm/io/fsq/twofishes/indexer/data/logback.xml']
Update it with the max memory argument -Xmx10g:
jvm_args = ['-Dlogback.configurationFile=src/jvm/io/fsq/twofishes/indexer/data/logback.xml', '-Xmx10g']
Also, when running parse.py with the '--output_revgeo_index' argument for processing the shapefile for reverse geocoding, I ran into the following error:
Exception in thread "main" io.fsq.rogue.RogueException: Mongo query on geocoder [db.name_index.find({ "name" : { "$regex" : "^?" , "$options" : ""} , "excludeFromPrefixIndex" : { "$ne" : true}}).sort({ "pop" : -1}).limit(1000)] failed after 2 ms
... stacktrace removed for brevity ...
Caused by: com.mongodb.MongoQueryException: Query failed with error code 2 and error message 'Regular expression is invalid: invalid UTF-8 string' on server 127.0.0.1
This error halts the parsing job, and corrupts the database/index(es). I wasn't the only one who encountered this; it was already logged as an issue. Needing to solve this, I figured out that the error was bubbling up, causing the service to fail. I was able to temporarily get past this build error, and avoid the corrupted index by editing fsqio/src/jvm/io/fsq/twofishes/indexer/output/PrefixIndexer.scala to add a try/catch block around the section of code where the error occurs (example below). This traps the error and just keeps on processing the remaining prefixes. In the current version of this file, that means enclosing lines 115 through 140 with the try/catch.
for {
(prefix, index) <- sortedPrefixes.zipWithIndex
} {
if (index % 1000 == 0) {
log.info("done with %d of %d prefixes".format(index, numPrefixes))
}
try {
val records = getRecordsByPrefix(prefix, PrefixIndexer.MaxNamesToConsider)
val (woeMatches, woeMismatches) = records.partition(r =>
bestWoeTypes.contains(r.woeTypeOrThrow))
val (prefSortedRecords, unprefSortedRecords) =
sortRecordsByNames(woeMatches.toList)
val fids = new HashSet[StoredFeatureId]
//roundRobinByCountryCode(prefSortedRecords).foreach(f => {
prefSortedRecords.foreach(f => {
if (fids.size < PrefixIndexer.MaxFidsToStorePerPrefix) {
fids.add(f.fidAsFeatureId)
}
})
if (fids.size < PrefixIndexer.MaxFidsWithPreferredNamesBeforeConsideringNonPreferred)
{
//roundRobinByCountryCode(unprefSortedRecords).foreach(f => {
unprefSortedRecords.foreach(f => {
if (fids.size < PrefixIndexer.MaxFidsToStorePerPrefix) {
fids.add(f.fidAsFeatureId)
}
})
}
prefixWriter.append(prefix, fidsToCanonicalFids(fids.toList))
} catch {
case e: Exception => println("Skipping due to error processing prefixes")
}
}
I have forked the TwoFishes code to make this change to PrefixIndexer.scala, and submitted this pull request.
Next Steps
Check out Part 2 of this blog post to see how you can containerize, run and test this service.