Design and Test Considerations for an AWS Serverless Architecture


This post is a companion blog to a recent post on Building a Hybrid Mobile Application with Adobe Phonegap that I published in January. We recently released our Mobile Application on the Apple App Store. To supply the mobile application with a performant, scalable and elastic backend, I decided to experiment with an entirely serverless architecture using AWS API Gateway, Lambda and DynamoDB for the following reasons:
- Cost Efficiency: My primary driver in choosing a serverless architecture was to make the solution as cost efficient as possible. We run our web applications via stateless microservices in containers on EC2, and while that will scale, I didn't want to pay EC2 costs for the mobile backend to scale. Route 53, API Gateway, Lambda and DynamoDB pricing is incredibly cost effective. More on this later.
- Low Overhead/Maintenance: Managing a set of REST Interfaces, Lambda Functions and Dynamo Tables is much more lightweight than dealing with microservices/containers on EC2/ECS/EKS. For starters, a serverless architecture precludes me from having to worry about scaling/maintaining application servers.
- Infinite Scale and Elasticity: AWS asserts that API Gateway will scale to handle requests as needed, and Lambda will continue spinning up functions as needed to scale infinitely. DynamoDB is designed to handle massive load, with the only limitation being the Read Capacity Auto Scaling configuration you choose.
- Multi-Region Support: Around November 2017, AWS announced Multi-Region support for API Gateway, and Global Tables (replication) for DynamoDB.
- Curiosity: I wanted to try the latest thing to see how it worked, and if it met my expectations. I am using Java, which comes with some JVM overhead, and wanted to see if Lambda could perform.
In this blog, I'm going to suggest some best practices, and share some lessons that I learned by working with these services. I'm not going to step through the construction of a API Gateway->Lambda->DynamoDB sample application because there are plenty of good web resources on those topics.
Architecture
Here is a diagram that conceptually represents the architecture I have implemented. I will step through this one segment at a time.
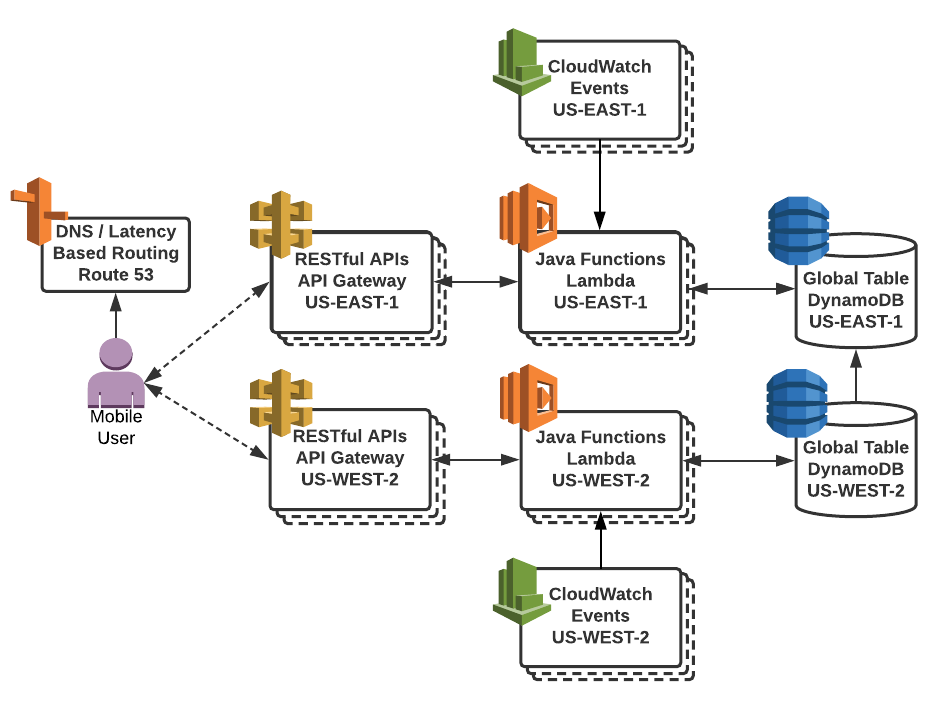
API Gateway
Multi-Region or Edge Optimized
The first decision I faced was whether to use an Edge Optimized or Multi-Region API Gateway configuration. At the present time, our users access the majority of our data services by geographic location. At query time, this becomes a latitude and longitude, which is going to be unique for every user. Therefore, it doesn't make as much sense for us to build a mobile backend that uses 'Edge Optimized' API Gateway endpoints. The reason is that the vast majority of queries coming from the mobile app containing those unique latitude/longitude coordinates are going to pass through CloudFront Edge Caching and go direct to Lambda/DynamoDB. Because our users are geographically dispersed across the United States, it makes more sense for us to replicate the backend to multiple AWS Regions for better performance/responsiveness. Before November of 2017, if you wanted to use API Gateway, Edge Optimized was your only choice.
With the advent of multi-region API Gateway support, and Dynamodb Global Tables, it became possible to easily build a geographically distributed serverless architecture. And with Route 53 Latency Based Routing (LBR), we can send our mobile users to the endpoint that is closest to their geographical location.
It is super easy to setup a multi-region gateway configuration. Stefano Buliani at AWS provides a great walk-through for this that leverages CloudFormation to wire up LBR in Route 53.
Unfortunately there is no way to synchronize or replicate API Gateway Resources across regions (yet). This means we have to create it in one region, and use the Swagger Export to get JSON, and then import that Swagger JSON to the other Region. I waited till I was nearly finished building out my API in one region before I bothered setting up the second region so that I didn't have to manually synchronize changes.
Stage Variables and Lambda Function Versions
If you follow the tutorial that I linked to above for setting up a multi-region API Gateway instance and Route 53 LBR, you will notice that you can version the API when you connect a Custom Domain Name. This occurs when you select a Path (e.g. they use "v1" in their example) while setting up the Path for the Base Path Mapping.
This is nice for a couple reasons. First, its cleaner than calling the Stage URLs, and provides a nice abstraction for easily versioning your API calls for subsequent API releases (e.g. mapping /v1/ to a prodv1 stage, and /v2/ to a prodv2 stage, etc). Second, it gets us thinking about using Lambda Versions and Aliases as well. I'll touch on the Lambda portion of this below. But for API Gateway, there is a blog on using Stage Variables. Buried at the end of that blog is an example of using a Stage Variable to reference a Lambda Alias (which is tied to a version). When you select the Lambda you want to use for a API Gateway Method, you can include a reference to a Stage Variable. In Ed Lima's example, he uses the Stage Variable 'lambdaAlias', but you can create a variable for different Lambda functions and aliases.
MyFunction:${stageVariables.myFunctionNameV1}
When you create the Stage Variable, you set the value associated with 'myFunctionNameV1' maps to a value that matches a Lambda alias. In the image below, I map this to 'version1'. As long as MyFunction has a 'version1' alias, this will work.

Using stage variables in concert with Lambda Aliases (versions) to version your API is better, I believe, than creating multiple, entirely new Lambda Functions for each version of your production API. In the end, this approach allows you to have fewer Lambda functions, with multiple versions which is easier to manage/keep track of. All you need to do is create new Stage Variables and update your references when updating your API Gateway Resources before publishing to a new stage.
The only downside to this is that you will need to grant permission for API Gateway to trigger that specific version of your Lambda function. Ed Lima explains this in his blog using the AWS CLI.
Canary Release Deployments
I haven't started using this yet, but Canary Release Deployments sound interesting. Recently released in November 2017, this essentially allows us to reuse our Stages, rather than creating separate stages for each release. It allows you to release updates to an existing stage, say 'production', but keeps those updates in a separate layer, called a Canary. You can then direct a percentage of requests (between 0 and 100%) to the Canary stage and analyze the success/failure of those new APIs. As your confidence increases with the API updates, you can send more traffic to the canary or promote it to full release (which then frees up the Canary for future updates to test). You can read more about setting up a Canary here.
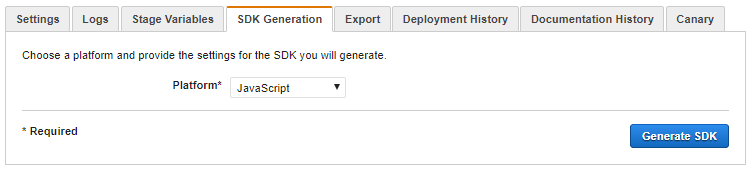
SDK Generation
One very nice feature of API Gateway for use with Mobile development is SDK Generation. Because we are using this backend for our hybrid mobile application, exporting a Javascript version of the SDK came in especially handy.
Lambda
Publishing Function Versions
You can take a look at the AWS Service documentation on publishing versions of your Lambda functions.
Environment Variables
When doing a multi-region setup, Environment Variables make it easy to externalize your configuration (e.g. details like Regions for connection objects, etc) and reuse your functions in different regions. AWS provided a nice introductory blog to Environment Variables in javascript. To access an environment variable from Java code, simply do the following:
System.getenv("ENVIRONMENT_VAR_NAME");
The Relationship between Memory and CPU
Next, I strongly encourage you to read about Lambda resource configuration. I want to highlight one sentence from that page:
"AWS Lambda allocates CPU power proportional to the memory by using the same ratio as a general purpose Amazon EC2 instance type, such as an M3 type. For example, if you allocate 256 MB memory, your Lambda function will receive twice the CPU share than if you allocated only 128 MB."
While it is not entirely intuitive that the Memory setting also influences CPU power when looking at the Lambda console, this is a critical piece of information to know. Let's look at a real world example.
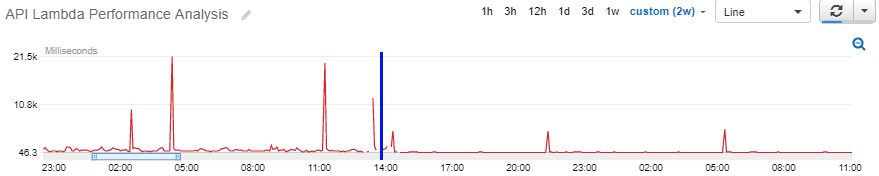
The CloudWatch Metrics graph above displays the execution duration (in milliseconds) of a single Lambda Function (that queries Dynamo) every 5 minutes. I placed a blue vertical line on the graph to mark the approximate time that I changed the memory configuration from 256 Mb to 1024 Mb. Notice the peaks drop significantly from between 10 and 21 seconds to around 5 seconds. I'll explain what causes these peaks in a moment when I address the Function Lifecycle. Also notice that the amplitude modulation of the line to the left of the blue marker is much more defined and much flatter to the right. This demonstrates the difference in CPU power between memory settings.
Function Lifecycle
Now, let's take a look at the Lambda execution model; I want to highlight two pieces of information. First, a quote from AWS on the Execution Context and the Cold Start:
"Execution Context is a temporary runtime environment that initializes any external dependencies of your Lambda function code, such as database connections or HTTP endpoints. This affords subsequent invocations better performance because there is no need to 'cold-start' or initialize those external dependencies, as explained below."
If you have done extensive testing with Lambda, then you are probably familiar with cold starts. For instance, when you execute a function for the first time after an upload, or after more than ~7 minutes of downtime in between queries. AWS highlights the reason for this in the quote below:
"It takes time to set up an Execution Context and do the necessary 'bootstrapping', which adds some latency each time the Lambda function is invoked. You typically see this latency when a Lambda function is invoked for the first time or after it has been updated because AWS Lambda tries to reuse the Execution Context for subsequent invocations of the Lambda function."
If you query the function again (less than ~7 minutes) after the function has been warmed (execution context creation and bootstrapping), it responds much quicker. Let's take a second look at the graph from before (copied below for convenience).
Notice the 5K millisecond peaks to the right of the blue vertical line at ~14:20 hrs, ~21:20 hrs, and ~5:20 hrs. Even though the function is being called every 5 minutes and generally performs sub-second, the peaks demonstrate that roughly every seven hours (give or take), the execution context and container are discarded and the function is bootstrapped again. Something to be aware of.
Because we configured this function for 1024 Mb of Memory, it now only takes 5 seconds, rather than 10 to 20 seconds from a cold start. I recommend setting all your functions to a minimum of 1024 Mb of Memory because this will improve the speed with which the Execution Context and Bootstrapping occurs.
While debugging a Lambda function, I noticed that the vast majority of the slowness in those cold starts is related to (1) Instantiating AWS Connection Objects and (2) Forming Secure Connections. It seems logical that the first time these are executed, the connection is written to the Execution Context and other Bootstrapping functions are performed ... like generating random numbers for TLS connections using SecureRandom. I found (by using ClientConfiguration) that the default SecureRandom algorithm in the AWS Java SDK is NativePRNG. There is a good blog on the topic of SecureRandom.
Because we are just releasing the mobile application, and I don't expect queries to come through frequently enough (fewer than 7 minutes apart) to keep the Lambda functions warm, I decided to use Scheduled CloudWatch Events to call the functions at five minute intervals. This definitely helps to improve overall application responsiveness for the user. However, it is not a silver bullet, because I'm only warming one instance of each function.
If my application suddenly goes viral (I can dream, right?), and thousands of users suddenly hit the backend, then more instances of these functions will cold-start. In the future, I want to collect some metrics using an API testing suite such as BlazeMeter.
Scheduled CloudWatch Events
There are a couple applications offered on the web (such as the WarmUP Plugin) that may fit some use case, but there is also an AWS native approach to this problem using Scheduled CloudWatch Events.
To create a scheduled event, I'll step through the Console quickly. When you go to CloudWatch, select Events, and click the 'Create Rule' button, and select the "Schedule" radio button under Event Source. Next, if you click the 'Add target' button, and expand the 'Configure input' area and select the 'Constant (JSON text)', then you will see the screen below.
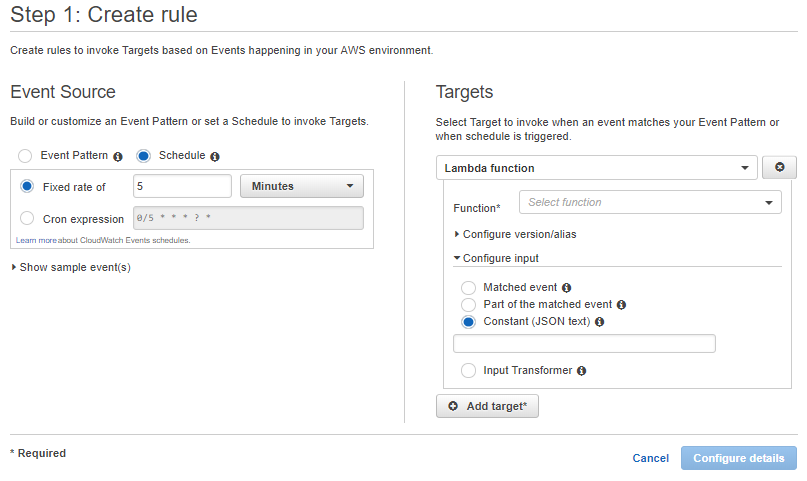
The default Scheduled event has a fixed rate of 5 minutes; I decided to go with this, based on my research. Next, you will want to select your Function from the 'Function dropdown' under Targets. Lastly, you can put in JSON text to send to your function. I used this to pass an instruction to my function.
{ "instruction": "warmer" }
For the function to get this, you will need to define an input type if you are using Java like I am. I simply have a String named 'instruction' in my RequestClass Pojo, and use that to make decisions in my Lambda function. By passing 'warmer' in for the 'instruction' String, I perform some initial setup and then exit the function to save on cost.
Once you fill in this information, you can click 'Configure details' and enter a Name and Description for the Event, and ensure the State is set to 'Enabled'. Once you submit, your function will be called every five minutes.
While it is easy enough to add a Scheduled CloudWatch Event using the AWS CLI, it is a bit verbose. The example at the link above steps through a basic example, but to add input, in the form of JSON as we did in the Console example above, you will want to examine the put-targets command. Specifically, look at the --targets option JSON structure to see how to pass a JSON string as an input to your function.
Using a Scheduled CloudWatch Event helps the most if you establish your connection objects before exiting. That way, the connections are maintained in the execution context. Otherwise, you will still pay a penalty establishing those connections even when querying a warm function for the first time.
DynamoDB
DynamoDB Global Tables provide replication of data changes to designated tables across regions. This is perfect for our needs, as DynamoDB can securely be accessed outside our VPC. This precludes us from having to run the Lambda functions inside the VPC, which attaches a new Elastic Network Interface (ENI), adding seconds to the Execution Context / Bootstrapping timetable.
AWS provides a nice walk through to get up and running with Global Tables. Setting up replication with another Region is very straight forward, so I won't duplicate that here. One thing of note is that any changes to Auto-Scaling Groups, or setting up/configuring Global Secondary Indexes will need to be done in both regions. Those elements do not propagate.
Low Variable Cost
Our solution benefits from the 'Always Free' Tier, which includes:
- Lambda: 1 Million Requests and 400,000 GB-seconds of Compute per month. A GB-Second means that if you allocate 1024 Mb of memory for the Function, you will receive 400k seconds for free each month. Less memory equals more free seconds, and allocating more memory equates to less free seconds.
- DynamoDB: 25 GB of Storage in DynamoDB
- Route 53: $0.600 per one million LBR queries
- API Gateway: $3.50 per one million API Gateway calls
There are Out-to-Internet data transfer charges as the responses travel up the stack.
Regarding our earlier recommendation to use Scheduled CloudWatch Events; these have little impact on the free tier we describe above. There are approximately 43800 minutes per month. At five minute intervals, that equals 8760 events, which doesn't even put a dent in the 1M free requests for Lambda's Always Free Tier. And if you exit the function swiftly, you should only be charged 100 ms on the calls to a warm function, which equates to:
8760 events * 100 ms = 876,000 ms / 1000 ms = 876 seconds
Subtract this from 400,000 free seconds per month, and we have 399,124 seconds remaining for your users before you are charged for capacity beyond the free tier.
Troubleshooting/Debugging
My preference is to test early and often. Lets start with Lambda, and end on API Gateway.
There are a number of ways to get started with Java Lambda functions. AWS provides a few here. And there are two ways to test Lambda functions. The first is to use unit testing with the AWS Toolkit for Eclipse. I also found and incorporated a good tool for mimicking Environment Variables in my unit tests.
Also, you can use serverless application model templates with the Serverless Application Model Local developer tool. AWS has a great blog that provides a step by step guide.
Once you deploy the jar to AWS, you can test within the Lambda Console. AWS has improved upon this feature, and provides a guide online. This test is useful to see how Lambda behaves 'in the wild' independently. This feature lets you put JSON strings directly into the test event, which you can also reuse in the API Gateway Console test after you've connected your Method to a Lambda function.
You will also want to use an execution IAM Role that grants your Lambda function permission to publish to CloudWatch Logs:
"If your Lambda function code accesses other AWS resources, such as to read an object from an S3 bucket or write logs to CloudWatch Logs, you need to grant permissions for relevant Amazon S3 and CloudWatch actions to the role."
Pushing your logs to CloudWatch Logs makes it easy to debug your Lambda function. You can read more about accessing CloudWatch Logs for your Lambda function(s) here.
One last testing consideration for Lambda is whether or not to use AWS X-Ray. This concept is a nifty one, similar to OpenZipkin, which is based on Google's Dapper. X-Ray leverages the request Trace ID created by AWS, and Spans (or segments) within your code and its own AWS SDKs to create charts that visually display performance timelines for each segment of your code. This helps identify bottlenecks in your application. You probably want to mark a span in the same way you would write Debug log statements. AWS provides information on using X-Ray with Java, X-Ray with Lambda, and X-Ray for API Gateway. I find X-Ray more useful at scale for providing a total performance picture for a Serverless Architecture in Test and Production than I do when doing the initial debugging of individual Lambda functions during development.
I referenced API Gateway Canary Deployments earlier. This looks like a neat idea for testing APIs already in production with your users. For API Gateway Resources that you want to test personally, you have two options: (1) test inside the API Gateway console, or (2) use Postman; and follow AWS' guide on using Postman with API Gateway.
For testing inside the API Gateway Console, select your API, and go to the Resources page. Select a Method on one of your resources, and you'll see a page that looks similar to the one below.
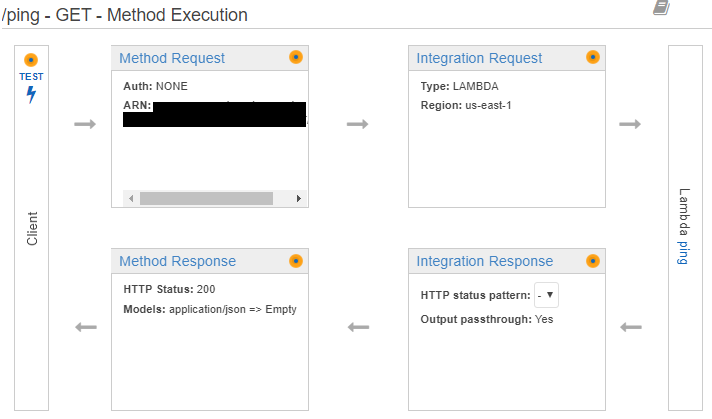
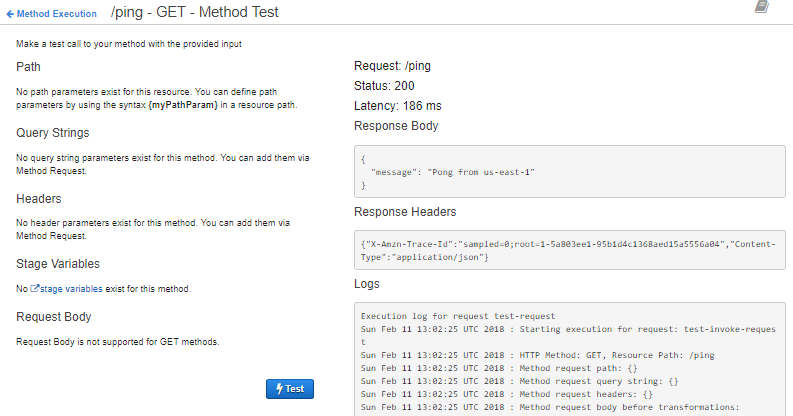
If you click on 'Method Request', you can define query parameters, headers, a request body model, and other settings. If you then return to 'Method Execution' (link will appear at the top of the panel), then you can click Test. If this is a Get Method, you simply click the blue 'Test' button. If it is a Post Method, you will see a Request Body textarea where you can put JSON. You get the idea. Below I posted a screenshot of the results from my /ping Get Method Test.
Further Research and Future Performance Enhancements
There is very little data on optimizing the performance of DynamoDB. While I was looking into the performance of Lambda execution, I stumbled across several sites that recommended the necessity of understanding ClientConfiguration defaults as they relate to DynamoDB. One blog post provided some good recommendations for changing the timeout settings. Another blog post suggested it was a good idea to turn off metadata caching. I did turn off metadata caching, but haven't had much need to do anything else. Something to examine.
This architecture affords us some additional breathing room to grow. For starters, we could add additional Regions in the U.S. to bring our service closer to more users. Again, because most of our queries are unique (using latitude/longitude), caching won't speed up our the vast majority of mobile queries.
We can increase Memory (and thereby increase the CPU power) on the Functions. This will further reduce the impact of the cold start. I do not have any detailed metrics on how much of an improvement this provides; it is something I may measure in the future.
We can use API Gateway Caching to further enhance performance. This will cache Lambda responses, which may help if we add new features that return generally common results. Likewise, we could also create CloudFront distributions in front of the Regional API Gateway endpoints. Documentation on this is sparse, but it is touched on in this AWS Forum Q/A, for which you must have an AWS account to access. There is also a post on Stackoverflow which addresses this as well.
DynamoDB is fast enough, but having the data in memory can help for read-optimization. There are two possible solutions. The first is DynamoDB Accelerator (DAX). This service, still relatively new (released in June 2017), will create an in-memory version of your DynamoDB Table(s). This requires on-demand r3 or r4 instance types to host the DAX cluster (one to ten nodes), as no option exists yet for reserved instances. This can get a little pricey. Alternatively, we could use ElastiCache Redis or Memcached.